1 前言
这是 KV Cache 系列的第二篇,接着上一篇[[KV Cache(一):从KV Cache看懂Attention(MHA、MQA、GQA、MLA)的优化]]继续往下走。
这篇确确实实写的比较长,涵盖了 MQA/GQA 的拆解计算和 MLA 的完整推导。本来想着用例子讲的细一点,没想到这么长,但是再拆又有点断裂连贯性。所以就还是这么长,大家还是先存后再看吧
2 TL;DR
本文完整对比 MHA、MQA、GQA、MLA 四种 Attention 方案在 KV Cache 优化上的表现,每一步都用具体数字算清楚。核心问题是:每种方案到底能省多少?代价是什么?瓶颈卡在哪?
我们用一个基准场景:LLaMA-2-7B(FP16) + RTX A6000(48GB,768 GB/s),seq=4096,BS=1 起步。MLA 部分额外引入 DeepSeek-V2 的参数做对比。全文聚焦 Decoding 阶段,不涉及 Prefill 和训练。
内容分两大块:
MQA/GQA 篇:
- 结构差异:从代码和 config.json 看 MHA → GQA → MQA 改了什么
- 压缩的天花板:KV Cache 压下去了,比较MHA、GQA、MQA的压缩效果。
- BS 平衡点:通过提升BS来均摊模型参数的搬运量,能否让计算和搬运追平?
MLA 篇: 4. 以算换存:低秩压缩 KV → latent vector,用闲置算力换搬运时间 5. 矩阵吸收:把 Up-Projection 吸收进权重矩阵,推理时跳过解压 6. Compute Bound 翻转:head 数量决定 MLA 能否翻转瓶颈,DeepSeek-V2(
3 问题回顾
上一篇中我们已经详细介绍了 Prefill/Decoding 两阶段、KV Cache 原理、显存占用计算等内容,这里快速回顾核心结论:
- Decoding 阶段是 Memory Bound:每生成一个 token,都要把 KV Cache 从显存搬到 SRAM,搬运时间远大于计算时间
- 内存墙问题:搬运时间和计算时间差距非常大,GPU 大部分时间在等数据
- Attention结构优化来减少Memory Bound:
- MQA和GQA:通过模型结构上减少KV的数量来减少缓存。
- MLA则采用了另一种思路进行优化。
这篇通过一个实际场景案例进一步展开这个问题。接着从MQA和GQA说。
4 MQA和GQA结构
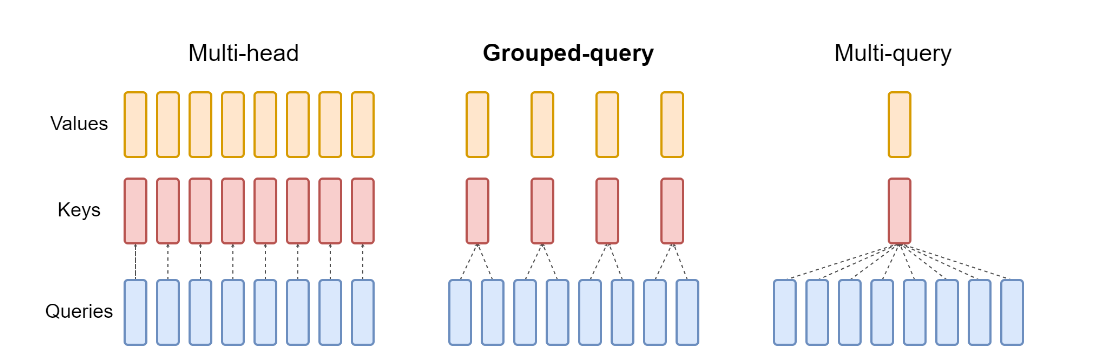
MHA、MQA、GQA 三者其实改动很小,思想上就是从KV完全一一对应到分组对应。所以代码结构几乎完全相同。我们可以用一份代码去看出改动区别。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class UnifiedAttention(nn.Module):
"""MHA/GQA/MQA 统一实现,只靠 num_kv_heads 区分。"""
def __init__(self, d_model, num_heads, num_kv_heads=None):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# ---------- [差异1] KV 头数 ----------
# MHA: num_kv_heads == num_heads(默认)
# GQA: num_kv_heads < num_heads,比如 2
# MQA: num_kv_heads = 1
self.num_kv_heads = num_kv_heads if num_kv_heads is not None else num_heads
self.num_kv_groups = num_heads // self.num_kv_heads
assert num_heads % self.num_kv_heads == 0
# ---------- [差异2] K/V 投影维度随 KV 头数缩小 ----------
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.out_proj = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
B, L, _ = x.shape
q = self.q_proj(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(B, L, self.num_kv_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(B, L, self.num_kv_heads, self.head_dim).transpose(1, 2)
# ---------- [差异3] GQA/MQA 需要把 KV 头复制到和 Q 一样多 ----------
if self.num_kv_groups > 1:
k = k[:, :, None, :, :].expand(B, self.num_kv_heads, self.num_kv_groups, L, self.head_dim)
k = k.reshape(B, self.num_heads, L, self.head_dim)
v = v[:, :, None, :, :].expand(B, self.num_kv_heads, self.num_kv_groups, L, self.head_dim)
v = v.reshape(B, self.num_heads, L, self.head_dim)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
output = torch.matmul(F.softmax(scores, dim=-1), v)
return self.out_proj(output.transpose(1, 2).contiguous().view(B, L, self.d_model))
mha = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=8)
gqa = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=2)
mqa = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=1)从 MHA 改为 MQA/GQA,代码上只改了 3 个地方(对应上面代码的 [差异1/2/3]),逐个看一下:
4.1.1 变量定义:KV 头的数量
所有差异其实都是引入了num_kv_heads
以 num_heads=32 为例:
- MHA: 原始实现中没有
num_kv_heads,K/V 头数天然等于num_heads - GQA: 引入
num_kv_heads = 8,每 4 个 Q 头共享 1 组 KV(共 8 组,num_heads / num_kv_heads = 32 / 8 = 4) - MQA: 引入
num_kv_heads = 1,所有 32 个 Q 头共享同一组 KV
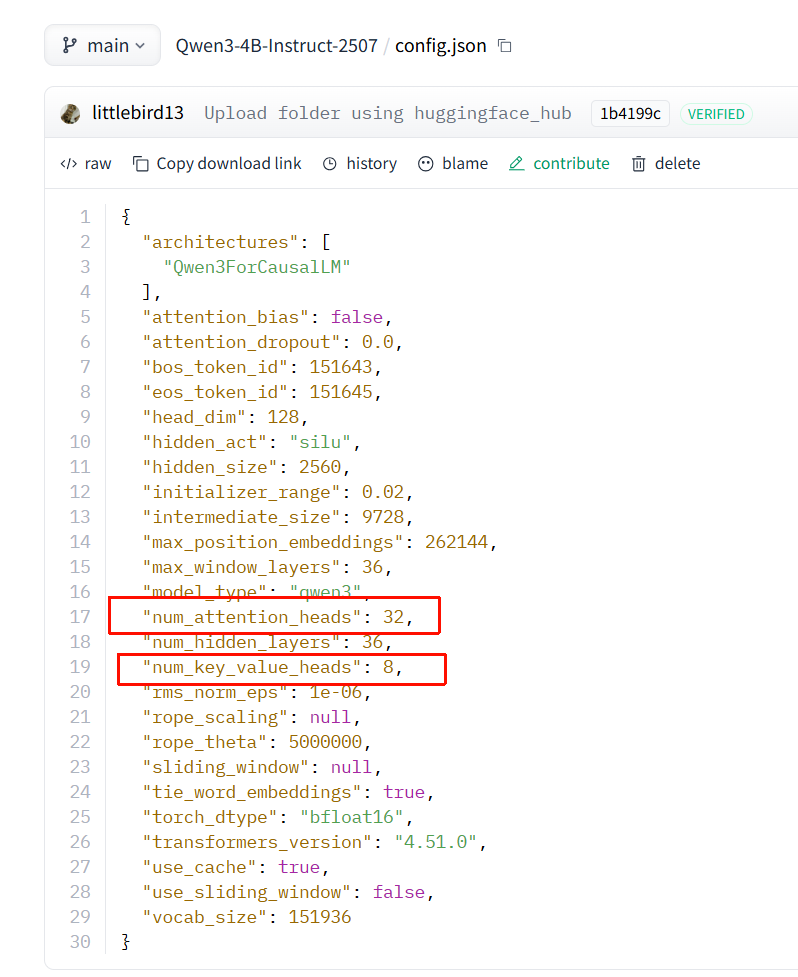
通过config.json其实能直观的看出来不同attention区别。num_attention_heads和num_key_value_heads的数量对比。同样多的就是MHA,num_key_value_heads少于num_attention_heads就是MQA或者GQA,如果num_key_value_heads = 1就是MQA了,如果不是1,那就是GQA了。
4.1.2 模型结构:线性层维度
第二个修改是 nn.Linear,因为 KV 头数变少了,K 和 V 的投影矩阵(权重矩阵)变小了,参数量也随之减少。
# ---------- [差异2] K/V 投影维度随 KV 头数缩小 ----------
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.out_proj = nn.Linear(d_model, d_model, bias=False)还是以 d_model=512, num_heads=8, head_dim=64 为例:
- Q 投影:三者相同,始终是
Linear(512, 512),输出维度 =num_heads × head_dim = 8 × 64 = 512 - K/V 投影:这里是差异点
- MHA:
Linear(512, 512) - GQA (kv=2):
Linear(512, 128) - MQA (kv=1):
Linear(512, 64)
- MHA:
直观点理解:在这个例子中每个 head 的投影维度是 64,Q 始终保持完整的 8 个 head,输出维度为 8×64=512;而 KV 的输出维度取决于 KV head 的数量:GQA 有几组 KV head 就乘几个 64,MQA 则只有 1 组,输出维度仅为 64。
本质上,k_proj 和 v_proj 的输出维度从 num_heads × head_dim 变成了 num_kv_heads × head_dim,KV 头数越少,投影矩阵越小。
这样一来,KV Cache所需要缓存的内容就变少了。
4.1.3 前向传播:复制/广播
第三个修改,因为 Q 有 8 个头,而 KV 可能只有 1 个头(MQA)或 N个头(GQA),矩阵形状对不上,没法直接做点积计算:
如果是MQA,Q 和 K 的头数维度不同,需要显式处理才能进行批量矩阵乘法。GQA也是同理。
Q: [B, 8, L, 64] ← 8 个头
K: [B, 1, L, 64] ← 1 个头 (MQA)
K^T: [B, 1, 64, L]
Q @ K^T = [B, 8, L, 64] @ [B, 1, 64, L] = ??? ← 第二维 8≠1,需要扩展所以在这里,我们要做一个复制或者广播操作。
以 MQA(num_heads=8, num_kv_heads=1)为例:
- 只有 1 组 KV,但有 8 个 Q 头
- 计算时,Q[0]~Q[7] 都要和同一个 K/V 做 attention
- 为了让矩阵运算能批量进行,把唯一的 K 复制 8 份:
[K] → [K, K, K, K, K, K, K, K]
复制前: Q: [B, 8, L, 64] K: [B, 1, L, 64] ← 形状不匹配,无法 matmul
复制后: Q: [B, 8, L, 64] K: [B, 8, L, 64] ← 形状匹配,可以批量计算
实际计算:
Q[0] × K[0] → Attention Score[0]
Q[1] × K[0] → Attention Score[1] (同一个 K)
Q[2] × K[0] → Attention Score[2] (同一个 K)
...
Q[7] × K[0] → Attention Score[7] (同一个 K)再看看以 GQA(num_heads=8, num_kv_heads=2):
- 有 2 组 KV,8 个 Q 头,每 4 个 Q 头共享 1 组 KV
- Q[0]~Q[3] 共享 K[0],Q[4]~Q[7] 共享 K[1]
- 每组 KV 复制 4 份:
[K0, K1] → [K0, K0, K0, K0, K1, K1, K1, K1]
复制前: Q: [B, 8, L, 64] K: [B, 2, L, 64] ← 形状不匹配
复制后: Q: [B, 8, L, 64] K: [B, 8, L, 64] ← 形状匹配
实际计算:
Q[0] × K[0] → Score[0] ─┐
Q[1] × K[0] → Score[1] │ 共享 K[0]
Q[2] × K[0] → Score[2] │
Q[3] × K[0] → Score[3] ─┘
Q[4] × K[1] → Score[4] ─┐
Q[5] × K[1] → Score[5] │ 共享 K[1]
Q[6] × K[1] → Score[6] │
Q[7] × K[1] → Score[7] ─┘上面的代码没有实现推理时的缓存逻辑(逐步存储和复用 KV),但 k_proj 和 v_proj 产出的 k、v 张量的形状,就是实际推理中每一步要缓存到显存里的数据量。
从形状可以直接看出,MQA/GQA 下 KV Cache 要存的东西确实少了,相应地 Decoding 时需要从显存搬到计算核心的数据量也变小了,显卡摸鱼的时间更短,推理速度更快。
那么,~~古尔丹~~,代价是什么呢?
从代码上可以看出来,这种做法本质上说有损的。MHA我们知道是Q和KV是一对一的。一定程度上是有点冗余,但是也得到了理论上最好的输出效果,但是一旦想着减少KV的数量,那么输出自然就随之降低了。
这种人为的减少,代表着质量的下降。MQA就是减少的太多了,导致质量不理想。所以我们才有了GQA(目前仍是主流),减少一部分,但是又没到质量不能看的地步。
所以MQA/GQA对KV Cache的优化效果到底如何?
5 MQA/GQA的优化目标
说来说去,核心就两个问题:
- 显存占用:不做优化的MHA,KV Cache实在太大了。MQA/GQA能压缩多少?
- 显卡利用率:带宽不够和显存占用导致latency,本质上是计算单元在干等。最终落到compute-bound和memory-bound的平衡问题上。
这KV Cache的显存占用和latency其实是一个一体两面的问题。孤立地分析其中任何一个容易陷入死胡同。
首先,我们再看一下本文所讨论场景的具体的基准:
上一篇我们采用的是A100,这次要换到A6000上去做比较。主要是为了和引用的论文一致。
| 类别 | 参数 | 值 | 说明 |
|---|---|---|---|
| 模型 | Model | LlaMA-2-7B [https://huggingface.co/TheBloke/Llama-2-7B-fp16/blob/main/config.json] | 大约7B参数量,MHA 架构,fp16下的模型权重为13.5G |
| 32 | MHA 下 Q/K/V 头数均为 32 | ||
| 128 | 每个注意力头的维度 | ||
| 4096 | |||
| 32 | Transformer 层数 | ||
| Model Weights | ~13.5 GB | FP16 精度下的模型权重(6.7B × 2 bytes) | |
| 硬件 | GPU | NVIDIA RTX A6000 | 48GB GDDR6 版本 |
| Peak Compute | 155 TFLOPS | FP16 Tensor Core, dense | |
| Memory Bandwidth | 768 GB/s | GDDR6 显存带宽 | |
| 推理设置 | Precision | FP16 | 2 bytes per element |
| Sequence Length ( | 4096 | 上下文长度 | |
| Batch Size | 1/N | 请求批次 |
表 1:软硬件基线配置。以 LlaMA-2-7B + RTX A6000 为例。LlaMA-2-7B 本身是 MHA 架构,后续 GQA/MQA 的计算是假设性对比,如果将其改为 GQA/MQA 结构,KV Cache 会如何变化。
5.1 现状:我们还卡在内存墙里
上一篇,我们用MHA分析了延迟:
这个公式有个适用条件:计算时间远小于搬运时间,延迟完全由带宽决定。我们在A6000上看看情况。
MHA模式下,每个token的KV Cache占用:
算上context length为4096时,KV Cache =
每次decoding要搬运的数据:
- Weights: ~13.5 GB
- KV Cache: ~2 GB
- 总计: ~15.5 GB
A6000显存带宽768 GB/s,理想情况下:
计算时间呢?7B模型约14 GFLOPS,A6000 FP16 Tensor Core算力约155 TFLOPS(dense):
20.2 ms vs 0.09 ms,差了约224倍。
比上一篇A100上的187倍还严重。A6000带宽比A100低,而算力差距没那么大,这就导致计算单元更发挥不出来了。
5.2 压缩KV Cache:MHA vs GQA vs MQA
现在我们把MHA换成GQA和MQA,又能省多少呢?
GQA-8
4个Query共享1组KV Head,
Context = 4096时,KV Cache =
比MHA的2GB减少了75%。
这时候搬运时间:
从20.2ms降到18.2ms,省是省了,但好像...也没省多少?
因为Weights占了大头。KV Cache从2G压到0.5G,在总搬运量里只少了1.5G,被13.5G的权重稀释了。来看更极端的MQA。
MQA(
所有Query共享1组KV Head。
Context = 4096时,KV Cache =
比MHA减少了97%。
搬运时间:
单看这个数字还是惨不忍睹,计算单元依然在度假。
但我愚蠢的弟弟啊,这只是batch size=1的情况。一旦BS上去,情况又不一样了。
5.3 压缩KV Cache的真正意义
看到上面的比较,首先产生疑惑是:这样压下去,终究还是在memory-bound里打转。计算时间还是0.09ms,搬运时间还是要十几二十毫秒。显卡摸鱼的问题根本没解决啊?
确实。如果模型权重是大头,而KV Cache压缩量很少,我们还在内存墙里:只是从"搬15GB等0.09ms"变成"搬14GB等0.09ms"。
所以我们要综合考虑问题,省下来的带宽和显存,最终可以让我们增大BS,从而得到更高的吞吐量。
这可以让KV Cache占比逐步提高到和模型权重一样甚至远高于权重的地步,那么KV Cache中对Attention结构的优化效果就体现出来了。
如果KV Cache还是2GB,BS稍微一涨,普通显卡的显存一般都是爆掉了,带宽也是立马吃满,什么都做不了。
现在GQA把KV Cache压到0.5GB,MQA压到64MB。这意味着:
- 同样的48GB显存,Batch size能从1提升到4、8、甚至更高
- 或者我们可以把Context拉到更长,而不被显存卡脖子
我们似乎可以在任务里根据当前显卡找一个合适的吞吐量。
5.4 综合思考吞吐量提升带来的影响
当BS提升之后,计算时间会线性增长(GEMV → GEMM),而搬运时间的结构和计算时间不一样,因为模型权重是所有请求共享的。
把两者写成 BS 的函数,计算时间是标准的线性函数,过原点:
其中
而搬运时间是仿射函数多了一个截距:
其中
关键就在截距
而斜率
| 方案 | 斜率 | |
|---|---|---|
| MHA | 2 GB | 2.604 ms |
| GQA-8 | 512 MB | 0.667 ms |
| MQA | 64 MB | 0.083 ms |
两条线,一条从原点出发(计算),一条从 17.6ms 起步(搬运)。虽然计算时间的斜率很小(0.09 ms),但搬运时间有个巨大的"底座"
一个非常自然的想法就出来了:
是否存在一个batch size可以让权重被均摊的够多,从而让计算量上升的比搬运的多,而找到一个计算和搬运的平衡点?
只要 BS 够大,计算时间总有可能追上搬运时间,前提是计算的斜率
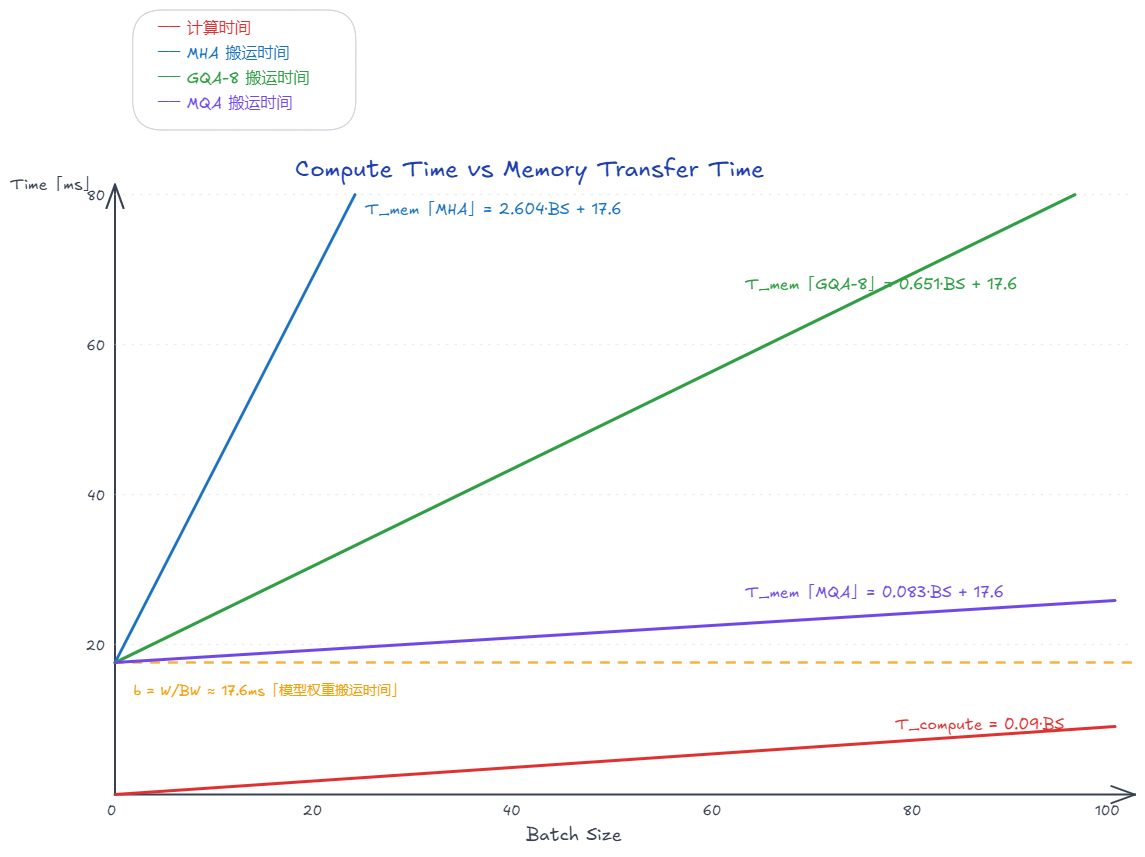
也就是说,在这个场景里,MQA的斜率是比计算的低的。这两条直线,随着BS的增大,最终会相交。GQA-8和MHA则绝对不可能。
让我们用一种不带脑子的方式,直接找几个不同的BS来试一下:
GQA/MQA让我们有机会把Batch拉上去。来看不同 BS 下的表现(seq=4096,RTX A6000-48GB):
| Batch Size | 方案 | Total KV Cache | Model Weights | 总搬运量 | 总延迟 |
|---|---|---|---|---|---|
| 1 | MHA | 2 GB | 13.5 GB | 15.50 GB | 20.18 ms |
| 1 | GQA (kv=8) | 512 MB | 13.5 GB | 14.00 GB | 18.23 ms |
| 1 | MQA | 64 MB | 13.5 GB | 13.56 GB | 17.66 ms |
| 8 | MHA | 16 GB | 13.5 GB | 29.50 GB | 38.41 ms |
| 8 | GQA (kv=8) | 4 GB | 13.5 GB | 17.50 GB | 22.79 ms |
| 8 | MQA | 512 MB | 13.5 GB | 14.00 GB | 18.23 ms |
| 16 | MHA | 32 GB | 13.5 GB | 45.50 GB | 59.24 ms |
| 16 | GQA (kv=8) | 8 GB | 13.5 GB | 21.50 GB | 28.00 ms |
| 16 | MQA | 1 GB | 13.5 GB | 14.50 GB | 18.88 ms |
| 32 | MHA | OOM | - | - | - |
| 32 | GQA (kv=8) | 16 GB | 13.5 GB | 29.50 GB | 38.41 ms |
| 32 | MQA | 2 GB | 13.5 GB | 15.50 GB | 20.18 ms |
| 64 | MHA | OOM | - | - | - |
| 64 | GQA (kv=8) | 32 GB | 13.5 GB | 45.50 GB | 59.24 ms |
| 64 | MQA | 4 GB | 13.5 GB | 17.50 GB | 22.79 ms |
这个表格说明了两个问题:
5.4.1 BS的平衡点是“理论存在”
看表格数据:GQA的情况下,BS 从 1 涨到 64,搬运时间从 18.23ms 涨到 59.24ms,计算时间约是
相比之前约224倍的差距而言是有明显的,量级上是有明显缩短的。不过依然存在计算和显存搬运的"摸鱼期"存在。
这证明了BS增加吞吐量,和我们之前直觉一定程度上是符合的:某些场景下,BS 上去之后,计算时间线性涨,搬运时间随着模型权重被均摊后(仿射函数),两者的差距会变小。
不过要注意:这个比值缩小是因为模型权重(截距
所以提升 BS 对 MHA/GQA 的作用是:摊薄模型权重的固定搬运开销,提高带宽利用率,但无法改变 Memory Bound 的本质。
那即使是 MQA,这个”平衡点”真的能达到么?
第一种情况是:如果我们继续加下去。在我们加到一定量的BS之后,显存墙就先来了,单张卡的显存总量马上就hold不住了。即使用了MQA,也会随着BS的增长而OOM。
于是就有了第二种情况:我们还是不死心,那就继续换场景,既然上下文长度是4096不行,我再继续减少到2048、1024 甚至 512。
只要长度够短,BS就能开的更高,模型权重进一步被分摊,而显卡的显存带宽再稍微强那么一点。
这个值,似乎就是可以达到的。
也就是说,我们加了那么多限定,才能找到一种在特定显卡,特定任务下让推理的decoding阶段的显卡性能完全发挥的场景。 而这个任务的要求就包括:
- 上下文够短
- BS够大
- 模型权重够大(被均摊的价值更高)
- 显卡的显存带宽够大
所以面对现在基本都是32k上下文起步的模型而言,这个BS的值,只能说是 “理论存在”。尤其是vllm这类框架在运行模型时就要求提前分配KV Cache。除非专用任务,通常不会把上下文限定的很低。毕竟大多数情况都是混合任务的,输入内容有长有短。
5.4.2 BS增加导致单个任务的推理增加了
另外一个值得一提的点是,当我们提升BS时,KV Cache的总量是上涨的,这导致显卡的总利用率(吞吐量)是上去了,但是单个推理的延迟增多了。 也就是说,随着BS的提升,对于队列中的每一个单独用户而言,相对于BS=1的时候,他等待每个 Token 生成的时间变长了。
当然,这种等待时间的增加在感知上并不强,我们其实是可以接受的。抛开MQA对效果的损耗,我们如果只讨论GQA。能够在A6000上,可以跑32-64的BS可以运用在很多场景下了。比如做一些简单的意图识别或者分类判断。一些lora微调后的7B/8B级别模型做4096长度内文本的抽取也是很好的选择。所以把BS撑上去带来的收益是显著的。
MQA的质量损耗太大,GQA似乎是一个不错的选择,但是它依然受限于显存带宽的搬运,就不存那种可以轻易达到计算和带宽搬运平衡的方案么?
于是,为了下面这碟醋,我们终于把上面的饺子包完了。现在,我们可以顺理成章的说说MLA。
6 MLA(Multi-head Latent Attention)
MLA(Multi-head Latent Attention)是一种通过低秩压缩大幅减少KV Cache的方法,在实践中几乎不损失模型性能。它利用矩阵吸收技巧来将瓶颈从memory bound推向compute bound的Attention架构。
6.1 MLA的思想
MQA/GQA 是"有损压缩":通过砍 KV Head 来减少搬运量,但模型能力会下降。
而且我们已经知道,大多数场景下,用了GQA,GPU 算力依然严重闲置。既然算力闲着也是闲着,能不能 主动增加计算量,来换取更小的传输量?
Compression via Computation也就是以算换存。只要解压计算的时间 < 节省的搬运时间,就是赚的。
- 存储时:把 KV 压缩成一个很小的 Latent Vector
- 推理时:用闲置算力把 Latent Vector "解压"回完整的 KV
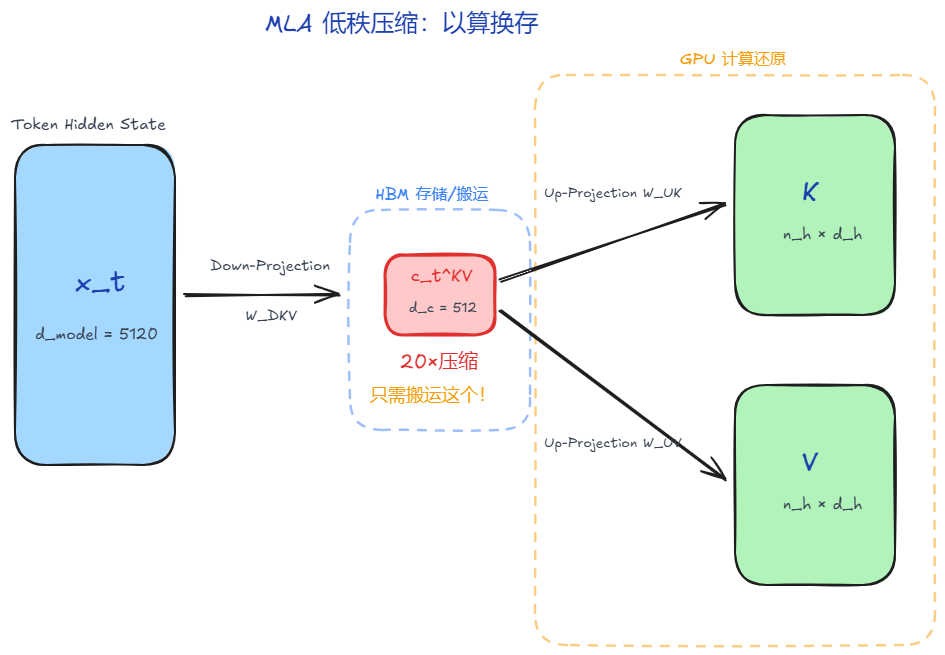
我们至少有两套矩阵,压缩的Down-Project和还原的Up-Project。可以分别表示为
搬运只要搬运
6.2 压缩:Down-Projection
MHA 的 KV Cache 回顾(符号沿用表 1):
前面我们算过,MHA 下每个 token 的 KV Cache 总占用是 :
那是跨所有层、带 FP16 精度的总字节数。
不过比较压缩比的时候,层数和精度对各方案都一样,会被约掉。所以接下来我们只看单层每 token 的元素数。
MHA 中,K 和 V 投影的输出都是
单层每 token 的 KV 元素数:
MLA 的压缩策略是引入 Down-Projection 矩阵
其压缩公式为:
这里要注意维度的变化,
显存节省对比(单层每 token 的元素数):
| 方案 | 每 Token 存储(元素数) | 相对 MHA |
|---|---|---|
| MHA | 1× | |
| GQA-8( | ||
| MQA( | ||
| MLA |
光看公式不直观,代入前文一直在用的 LlaMA-2-7B(
正常我们不能这样直接替换结构MLA到MHA/MQA/GQA的结构上,这里仅仅为了做一个比较说明。
| 方案 | 元素数 | 压缩比 |
|---|---|---|
| MHA | 1× | |
| GQA-8 | 4× | |
| MQA | 32× | |
| MLA( | 16× |
MQA 的压缩比就是
再看 DeepSeek-V2(
| 方案 | 元素数 | 压缩比 |
|---|---|---|
| MHA | 1× | |
| MQA | 128× | |
| MLA( | 20× |
注意这里 MQA 只是做个参考比较,我们都知道不会用它。MLA 的 20× 压缩比虽然不如 MQA 激进,但它是低秩压缩,保留了全部
换句话说,MQA/GQA 是在"压缩比"和"模型质量"之间做取舍,而 MLA 跳出了这个 trade-off。
6.3 还原:Up-Projection
压缩后的 Latent Vector 无法直接参与 Attention 计算。推理时需要"解压"。
Down-Projection 是逐 token 的,每来一个新 token,压缩成
Up-Projection 过程:
引入还原矩阵:
还原过程:
维度变化(注意,压缩的时候是1个1个到缓存,但是还原这里其实是
计算量分析:
Up-Projection 的 FLOPs(K 和 V 各一次矩阵乘法):
只要这部分的额外开销,没有超过memory-bound的部分就行。
6.4 以算换存到底赚不赚?
这种压缩再还原的思路其实很普通,有一种我上我也行的感觉。一般来说这个Up-Projection会有一定的限制,我们要考虑一下真的赚吗?
现在我们聚焦到单层 Attention来看一下赚不赚的问题。"以算换存"的 trade-off 发生在每一层内部,每层独立搬运自己的 KV Cache,独立做 attention 计算。用单层来看数字更干净,trade-off 一目了然。要算整个模型的量,乘以
场景设定(沿用表 1 基准配置 + 假设 MLA):
- 模型:LlaMA-2-7B,
, , - MLA 假设:
(沿用 DeepSeek-V2 的设定) - Sequence Length
,FP16 - 硬件:RTX A6000(768 GB/s 带宽,155 TFLOPS(dense))
当然,还是注意,LlaMA-2-7B 本身没有 MLA,这里是假设性对比,如果给 LlaMA-2-7B 加上 MLA(
6.4.1 第一步:存储对比
先看每层 Attention 的 KV Cache 大小(
| 方案 | 每 Token 存储(元素数) | 总大小(FP16) | 相对 MHA |
|---|---|---|---|
| MHA | 64 MB | 1× | |
| GQA-8( | 16 MB | 1/4 | |
| MQA( | 2 MB | 1/32 | |
| MLA( | 4 MB | 1/16 |
MLA 的存储量介于 GQA-8 和 MQA 之间,但不需要砍 KV Head。
6.4.2 第二步:搬运时间对比
在 A6000 上(768 GB/s),搬运这些 KV Cache 需要多久?
| 方案 | KV Cache | 搬运时间 |
|---|---|---|
| MHA | 64 MB | |
| GQA-8 | 16 MB | |
| MQA | 2 MB | |
| MLA | 4 MB |
光看搬运,MLA(0.0052 ms / 5.2 μs)比 GQA-8(0.021 ms / 20.8 μs)还快,比 MHA(0.083 ms / 83.3 μs)快了一个数量级。
但 MLA 有个 GQA 没有的额外开销:Up-Projection。
6.4.3 第三步:Up-Projection 的代价
上一节算过,Up-Projection 的 FLOPs,现在代入实际的数字:
在 A6000 上:
?!
0.222 ms(222 μs)?
比 MHA 的搬运时间(0.083 ms / 83.3 μs)还长?
如果真要在推理时把所有 latent vector 解压回完整的 K/V,那 MLA 反而更慢了。这不是亏成狗了吗?
压缩存储省了搬运时间,但解压计算又把时间加回来了。这怎么算都不对啊?
6.4.4 第四步:矩阵吸收
这里就是 MLA 最精妙的地方之一:实际上,你根本不需要解压。
通过一个叫矩阵吸收(Weight Absorption) 的技巧,MLA 可以让 Attention 直接在 latent space中计算,完全跳过 Up-Projection。
有点反直觉了,再回顾一下Attention Score 的计算过程。
不做吸收的原始计算,Score 的计算需要先把 latent vector Up-Project 回完整的 K,再和 Q 做点积:
这里为了看清结构,先写单个 head 的情况。
展开转置(
利用矩阵结合律,重新分组,把和输入无关的部分合并:
关键在于,
吸收后的推理流程:
注意维度变化:
对 V 侧也做同样的吸收(把
省掉了 Up-Projection 的 0.222 ms(222 μs)。但代价是每个 head 的 Attention 计算从
同时注意
计算量涨了约 4 倍。但单层的搬运量从 64 MB 降到了 4 MB,减少了 16 倍。
在 A6000 上:
| 方案 | 搬运量 | 搬运时间 | Attention FLOPs | 计算时间 | 总延迟 |
|---|---|---|---|---|---|
| MHA | 64 MB | 0.083 ms (83.3 μs) | 67 MFLOPs | 0.00043 ms (0.43 μs) | ≈ 0.083 ms |
| GQA-8 | 16 MB | 0.021 ms (20.8 μs) | 67 MFLOPs | 0.00043 ms (0.43 μs) | ≈ 0.021 ms |
| MQA | 2 MB | 0.0026 ms (2.6 μs) | 67 MFLOPs | 0.00043 ms (0.43 μs) | ≈ 0.0026 ms |
| MLA | 4 MB | 0.0052 ms (5.2 μs) | 268 MFLOPs | 0.0017 ms (1.73 μs) | ≈ 0.0052 ms |
6.4.5 以算换存的效果
MLA 把 Attention 层的延迟从 0.083 ms(83.3 μs)压到了 0.0052 ms(5.2 μs),16× 加速。
| 方案 | 搬运时间 | 计算时间 | 算力利用率 | 瓶颈 |
|---|---|---|---|---|
| MHA | 0.083 ms (83.3 μs) | 0.00043 ms (0.43 μs) | 0.5% | Memory Bound |
| GQA-8 | 0.021 ms (20.8 μs) | 0.00043 ms (0.43 μs) | 2.1% | Memory Bound |
| MQA | 0.0026 ms (2.6 μs) | 0.00043 ms (0.43 μs) | 16.5% | Memory Bound |
| MLA | 0.0052 ms (5.2 μs) | 0.0017 ms (1.73 μs) | 33.3% | Memory Bound |
MLA 的算力利用率从 MHA 的 0.5% 跳到了 33.3%。但它仍然是 Memory Bound,搬运时间(0.0052 ms / 5.2 μs)还是大于计算时间(0.0017 ms / 1.73 μs)。
换算到全层数(×32 层),MHA Attention 层总延迟约 2.67 ms,GQA-8 约 0.67 ms,MQA 约 0.08 ms,MLA 约 0.17 ms。
对比前文全模型搬运时间(十几到几十 ms),Attention 层本身在总延迟中占比很小,大头还是模型权重的搬运。
根据5.4部分的分析,我们关注的是整体搬运量(模型权重 + KV Cache)和整体计算量的关系。BS 增大时,模型权重(13.5 GB)只搬一次被均摊,KV Cache 随 BS 线性增长,两条线的交点就是平衡点。
那现在 MLA 在这个框架下表现如何?上面我们一直在看单层的 trade-off,现在把视角拉回整个模型,32 层叠起来,MLA 每个请求的 KV Cache 总量是多少?
MLA 每层只存一个
Context = 4096 时,KV Cache =
现在我们也把 MLA 加进第二部分的斜率表:
| 方案 | 斜率 | |
|---|---|---|
| MHA | 2 GB | 2.604 ms |
| GQA-8 | 512 MB | 0.667 ms |
| MLA | 128 MB | 0.167 ms |
| MQA | 64 MB | 0.083 ms |
MLA 的斜率介于 MQA 和 GQA 之间,约为 MQA 的 2 倍,因为
计算时间呢?MLA 的 Attention FLOPs 虽然涨了 4 倍(67 → 268 MFLOPs),但 Attention 在整个模型的 14 GFLOPS 中占不到 2%,
直接上表(seq=4096,RTX A6000-48GB):
| Batch Size | 方案 | Total KV Cache | Model Weights | 总搬运量 | 总延迟 |
|---|---|---|---|---|---|
| 1 | MHA | 2 GB | 13.5 GB | 15.50 GB | 20.18 ms |
| 1 | GQA-8 | 512 MB | 13.5 GB | 14.00 GB | 18.23 ms |
| 1 | MLA | 128 MB | 13.5 GB | 13.63 GB | 17.74 ms |
| 1 | MQA | 64 MB | 13.5 GB | 13.56 GB | 17.66 ms |
| 8 | MHA | 16 GB | 13.5 GB | 29.50 GB | 38.41 ms |
| 8 | GQA-8 | 4 GB | 13.5 GB | 17.50 GB | 22.79 ms |
| 8 | MLA | 1 GB | 13.5 GB | 14.50 GB | 18.88 ms |
| 8 | MQA | 512 MB | 13.5 GB | 14.00 GB | 18.23 ms |
| 32 | MHA | OOM | - | - | - |
| 32 | GQA-8 | 16 GB | 13.5 GB | 29.50 GB | 38.41 ms |
| 32 | MLA | 4 GB | 13.5 GB | 17.50 GB | 22.79 ms |
| 32 | MQA | 2 GB | 13.5 GB | 15.50 GB | 20.18 ms |
| 64 | MHA | OOM | - | - | - |
| 64 | GQA-8 | 32 GB | 13.5 GB | 45.50 GB | 59.24 ms |
| 64 | MLA | 8 GB | 13.5 GB | 21.50 GB | 28.00 ms |
| 64 | MQA | 4 GB | 13.5 GB | 17.50 GB | 22.79 ms |
MLA 的表现非常接近 MQA,BS=64 时总延迟 28 ms vs MQA 的 22.8 ms,而 GQA 已经飙到 59 ms。
更关键的是显存余量,BS=64 时 MLA 的 KV Cache 才 8 GB,加上权重 13.5 GB 也就 21.5 GB,离 48 GB 上限还远得很。
对比 GQA 在 BS=64 时 KV Cache 已经吃掉 32 GB,加上权重就快满了。
对比MLA 能撑到更大的 BS,而且不损失模型质量,这是 MQA 做不到的。
6.5 没有Compute Bound?
我们不是在找compute bound和memory bound的平衡点么?MLA现在看来,是有提升,但是也没有到达啊?
在 MLA 的解码过程中,我们利用矩阵结合律优化了计算路径:不还原完整的 KV,而是直接在压缩空间计算。
- 计算量(FLOPs):
- 搬运量(Bytes):
注意到一个点就是,这里
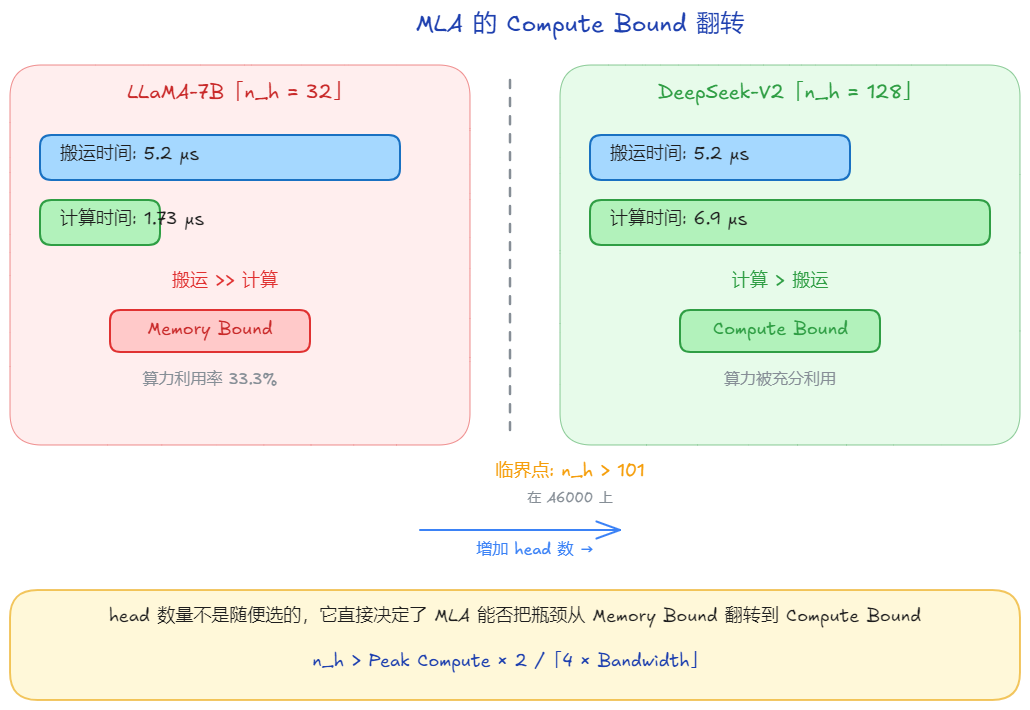
在我们的场景下,选的是 LlaMA-2-7B,它只有 32 个 head。
那需要多少个 head 才能翻转?令计算时间 > 搬运时间:
在 A6000 上,
这不就是Roofline Model么!对,我们通过近乎直觉和粗暴的方式,终于走到了这个框架下。之前的讨论都是基于整个模型的。而这里其实已经迈入对层和算子的分析了。下一篇我们会展开。
而 DeepSeek-V2 呢?
| 方案 | 搬运量 | 搬运时间 | Attention FLOPs | 计算时间 | 总延迟 | 瓶颈 |
|---|---|---|---|---|---|---|
| MHA | 80 MB | 0.104 ms (104 μs) | 84 MFLOPs | 0.00054 ms (0.54 μs) | ≈ 0.104 ms | Memory Bound |
| MLA | 4 MB | 0.0052 ms (5.2 μs) | 1.07 GFLOPs | 0.0069 ms (6.9 μs) | ≈ 0.0069 ms | Compute Bound |
在 DeepSeek-V2 上,MLA 的计算时间(0.0069 ms / 6.9 μs)终于超过了搬运时间(0.0052 ms / 5.2 μs),瓶颈从"等数据"翻转成了"在算数"。这才是"以算换存"的完整形态。
这也解释了 DeepSeek-V2 为什么要设计 128 个 head:head 数量不是随便选的,它直接决定了 MLA 能否把瓶颈从 Memory Bound 翻转到 Compute Bound。
但别急着下结论,
这里说的翻转仅限于 Attention 层内部。
当我们把视角扩展到整个模型的 Decoding 延迟还包括 FFN 等 Linear 层,也就是模型权重本身并没有看。Attention 在总延迟中的占比随序列长度增长而增大,短序列下这个翻转对端到端延迟的实际收益有限。(受篇幅限制,下一篇展开)
而前面的结论在 MLA 下同样成立:增大 BS 依然能均摊权重搬运,更长的上下文依然会推高 Cache 总量。
所以更准确的说法是:MLA 在架构层面提供了翻转的机会——通过压缩 Cache 同时拉高计算密度,让 Attention 层有可能跨过 Compute Bound的门槛的。但这个机会能不能兑现,取决于你的显卡(算力/带宽比)、你的 Batch Size、你的序列长度。
6.6 以算换存的核心逻辑
LlaMA-2-7B(
- 搬运减少 16×:64 MB → 4 MB
- 计算增加 4×:67 MFLOPs → 268 MFLOPs
- 净效果:Attention 延迟从 0.083 ms(83.3 μs)降到 0.0052 ms(5.2 μs)(16× 加速),算力利用率从 0.5% 提升到 33.3%
DeepSeek-V2(
- 搬运减少 20×:80 MB → 4 MB
- 计算增加 12.8×:84 MFLOPs → 1.07 GFLOPs
- 净效果:Attention 延迟从 0.104 ms(104 μs)降到 0.0069 ms(6.9 μs)(15× 加速),且瓶颈翻转为 Compute Bound
在 Memory Bound 的时候,减少搬运的收益远大于增加计算的代价。head 数量越多,"以算换存"的效果越彻底。
其实到这里,这种**压缩再解压**的思路**很多人都能想到**。甚至于想到矩阵吸收已经非常惊艳了。然而这里的推导会遇到一个关键问题:RoPE怎么办?
包括Deepseek和苏神都在这里进行过深入思考。
引用苏神原文:

6.7 RoPE 的挑战与 Decoupled RoPE
MLA 的数学逻辑看似完美闭环。但在工程落地时,遇到了一个棘手的问题:旋转位置编码(RoPE)。
6.6.1 RoPE 简述
Attention 本身不包含位置信息,打乱 token 顺序,Score 不会变。RoPE 通过对 Q 和 K 施加位置相关的旋转来注入位置信息。
具体来说,对于
其中
写成矩阵形式,就是一个分块对角的旋转矩阵
RoPE 有一个关键性质:
不管
6.6.2 矩阵吸收为什么失效
没有 RoPE 时,我们知道单个 head 的 Score(列向量表示):
现在加上 RoPE,我们强行试一下。Q 和 K 在投影之后、做点积之前,各自乘上位置相关的旋转矩阵:
展开转置:
问题出在
没有 RoPE 时,
6.6.3 那先压缩再加RoPE呢?
先把
然而RoPE 是为
6.6.4 解决方案:Decoupled RoPE
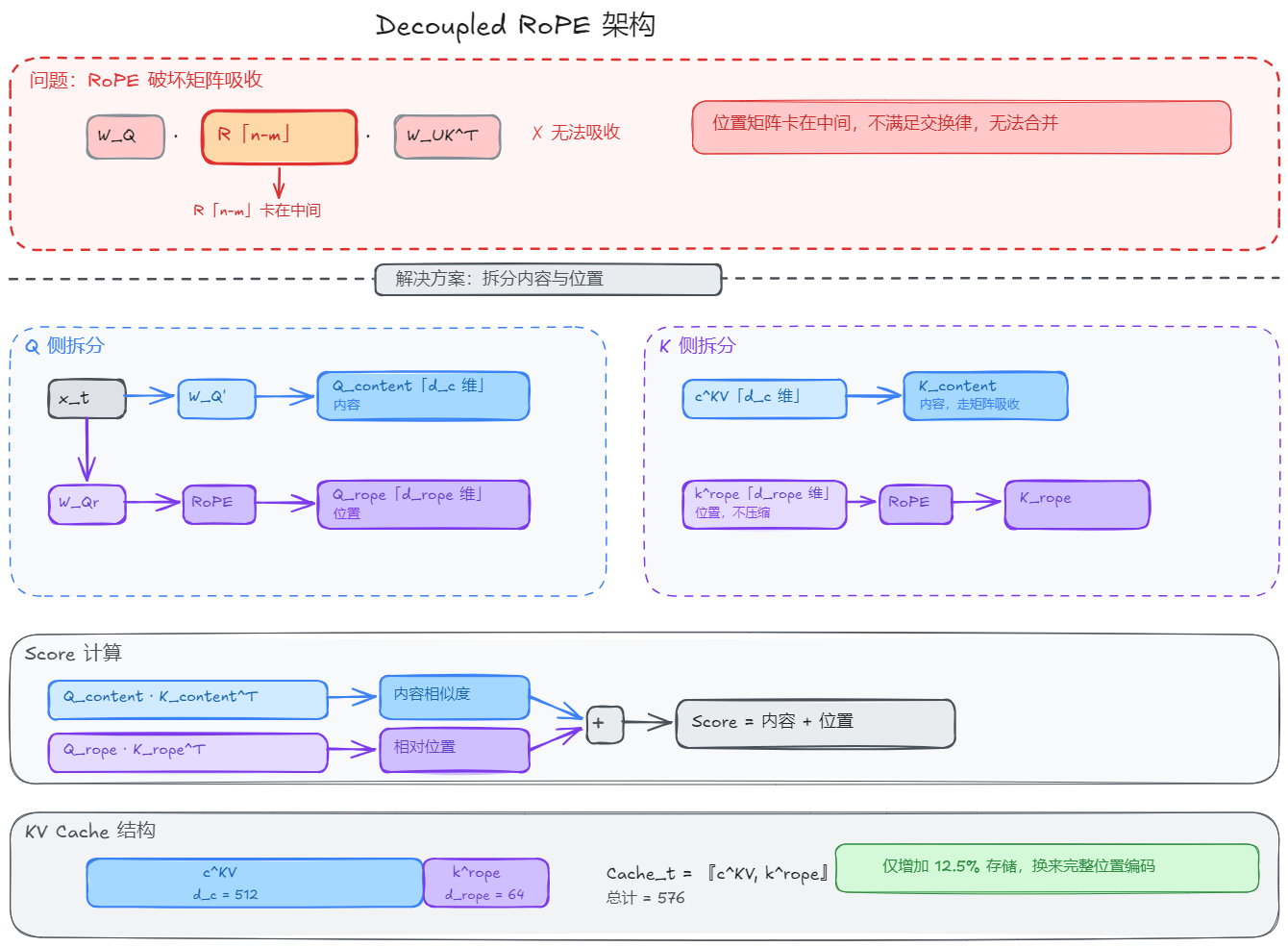
DeepSeek 的解决方式是既然 RoPE 和压缩不兼容,那就把它们拆开。
Attention Score 本质上编码了两种信息,内容相似度和位置关系。既然 RoPE 只负责位置,而低秩压缩只负责内容,那就让它们各管各的。(诶?有没有想起来之前单独谈位置编码的时候。[[为什么Embedding加上位置编码后不会破坏语义]])
具体来说,把 Q 和 K 各自拆成两部分:
K 侧:
- Content Key:不含位置信息,走 MLA 的低秩压缩 + 矩阵吸收
- 从
中恢复(吸收后直接用 )
- 从
- RoPE Key:只负责位置信息,不压缩,单独存储
,DeepSeek-V2 中
Q 侧也做对应的拆分:
- Content Query:
,维度 (吸收后) - RoPE Query:
,维度
最终 KV Cache 结构:
每 token 每层存储
| 方案 | 每 token 每层存储 | DeepSeek-V2 代入 |
|---|---|---|
| MHA | ||
| MLA(无 RoPE) | ||
| MLA(Decoupled RoPE) |
Attention Score 的计算:
因为标准 Attention 的 Score 本来就是 Q 和 K 的内积。把 Q 和 K 各自拆成两部分后:
这就是向量拼接后做内积的自然结果,分段内积之和等于整体内积。
两部分各司其职:
- 内容部分:享受矩阵吸收的全部好处,搬运的只有
- 位置部分:带 RoPE,不压缩,但
本身就很小,额外开销可以忽略
原始 Transformer 用加法混合语义和位置,四项全部耦合在同一组 $W^Q$、$W^K$ 里,靠训练去学分离,交叉项也得模型自己消化。
而 MLA 的 Decoupled RoPE 用拼接代替相加,拼接后内积天然等于分段内积之和,交叉项在数学上直接消失了。所以本质上是同一个认知,attention score 天然可分解为内容和位置两部分。只不过从"模型自己学着分"变成了"架构帮你分好"。
7 结语
好,到这里这篇就差不多了。
回头看,我们其实就干了一件事:拿具体数字算清楚 MQA/GQA 和 MLA 到底省了多少。
搞清楚我们到底有没有机会保持质量的前提下发挥显卡的所有性能。
GQA/MQA 的思路很直接,砍 KV Head,少存少搬,省下的显存拿去开更大的 batch。
而 MLA 直接把 KV Cache 压到低秩的 latent space,再通过矩阵吸收跳过 Up-Projection,用算力换显存带宽。
最后,本文主要是从 decoding 和模型整体+KV Cache推理的搬运量、延迟、计算量这个角度来切入的。而下一篇,会把 roofline model 和算子级别的视角补上。
8 符号与公式
8.1 符号表
| 符号 | 含义 | 说明 |
|---|---|---|
| 注意力头数(Q heads) | LLaMA-2-7B: 32,DeepSeek-V2: 128 | |
| KV 头数 | MHA: | |
| 每个头的维度 | LLaMA-2-7B: 128,DeepSeek-V2: 40 | |
| 模型隐藏层维度 | ||
| Transformer 层数 | LLaMA-2-7B: 32 | |
| MLA latent vector 维度 | DeepSeek-V2: 512 | |
| Decoupled RoPE 维度 | DeepSeek-V2: 64 | |
| 序列长度(context length) | 本文取 4096 | |
| Batch Size | 批次,本文中采用1-64 | |
| 模型权重大小 | LLaMA-2-7B FP16: ~13.5 GB | |
| 显存带宽 | A6000: 768 GB/s | |
| 单个请求的 KV Cache 总量 | 跨所有层、全序列长度 | |
| 第 | ||
| Down-Projection 矩阵 | ||
| Up-Projection 矩阵 | ||
| 吸收后的 Q 投影 | ||
| RoPE 旋转矩阵 | 位置 | |
| RoPE 基础频率 |
8.2 关键公式
KV Cache 每 token 大小(跨所有层,FP16):
| 方案 | 公式 | LLaMA-2-7B 代入值 |
|---|---|---|
| MHA | 0.5 MB | |
| GQA- | 0.125 MB( | |
| MQA | 0.016 MB | |
| MLA | 0.032 MB | |
| MLA(Decoupled RoPE) | 0.036 MB |
Attention FLOPs(单层,Decoding 生成 1 个 token):
| 方案 | 公式 |
|---|---|
| MHA / GQA / MQA | |
| MLA(吸收后) |
延迟与 Roofline:
| 公式 | 含义 |
|---|---|
| Memory Bound 下的近似延迟 | |
| 搬运时间随 BS 的仿射函数 | |
| 算术强度 | |
| AI < Ridge Point → Memory Bound |
Decoupled RoPE:
| 公式 | 含义 |
|---|---|
| 内容相似度 + 相对位置,分段内积 | |
| 每 token 缓存 |
9 参考
- DeepSeek-AI. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. 2024. https://arxiv.org/abs/2405.04434
- Shazeer, N. Fast Transformer Decoding: One Write-Head is All You Need. 2019. https://arxiv.org/abs/1911.02150
- Ainslie, J., et al. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. 2023. https://arxiv.org/abs/2305.13245
- 苏剑林. 缓存与效果的极限拉扯:从 MHA、MQA、GQA 到 MLA. https://kexue.fm/archives/10091
- 苏剑林. Transformer升级之路:21、MLA好在哪里?(下). https://kexue.fm/archives/11111
- Yuan, Z., et al. LLM Inference Unveiled: Survey and Roofline Model Insights. 2024. https://arxiv.org/abs/2402.16363
- Kipply. Transformer Inference Arithmetic. https://kipp.ly/transformer-inference-arithmetic/
- Pope, R., et al. Efficiently Scaling Transformer Inference. 2022. https://arxiv.org/abs/2211.05102
- Dao, T., et al. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. 2022. https://arxiv.org/abs/2205.14135
- Williams, S., et al. Roofline: An Insightful Visual Performance Model for Multicore Architectures. 2009. https://people.eecs.berkeley.edu/~kubitron/cs252/handouts/papers/RooflineVyNoYellow.pdf
- NVIDIA. RTX A6000 Datasheet. https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-product-literature/proviz-print-nvidia-rtx-a6000-datasheet-us-nvidia-1454980-r9-web.pdf
- Llama-2-7B-fp16. Hugging Face. https://huggingface.co/TheBloke/Llama-2-7B-fp16